Le guide du marketeur pour la création d’audiences CRM : de l’avantage des solutions plug & play de deep learning
10
décembre

Catégorie : IA for CRM
Avez-vous déjà douté du processus de création d’audience CRM de votre équipe ? Vous vous êtes déjà demandé si vos critères de création d’audiences étaient assez précis ? Ou comment il pouvait être aussi long et fastidieux de générer vos segments ? Ou peut-être vous êtes-vous tout simplement demandé : en 2021, n’y a-t-il vraiment pas de meilleure manière de faire ?
Ou bien, vous n’envoyez que des newsletters de masse, mais envisagez de mettre bientôt en place une approche plus ciblée ? Avec la dizaine de questions qui accompagnent ce projet : le traitement de vos données, la création d’audiences, les ressources internes…
Ou peut-être avez-vous simplement envie de découvrir comment fonctionne l’IA dans le domaine du marketing CRM B2C ?
Peu importe les raisons, je vais vous aider. Dans ce guide illustré, je vais vous expliquer, étape par étape, le problème des méthodes traditionnelles de construction d’audience et vous montrer pourquoi le Deep Learning est la seule manière de bien construire une audience CRM (ainsi que quelques autres applications pratiques dans le domaine du marketing CRM !).
Mais pour commencer, une petite remarque : cet article est un peu long.
Pour commencer, il convient d’établir quelques définitions, car les entreprises ont tendance à utiliser des termes différents pour les différents types de communications CRM.
Les communications CRM entrent généralement dans l’une de ces catégories :
Aujourd’hui, nous allons nous intéresser à ces campagnes ciblées. Elles représentent environ 90 % des messages CRM envoyés par une marque. Elles sont utilisées pour communiquer sur les nouvelles collections ou produits, les promotions, des catégories de produits spécifiques…
Généralement, les équipes CRM commencent par envoyer des campagnes batch & blast à l’ensemble de leur base clients. Cependant, elles constatent généralement très vite les limites de ce type de campagnes :
Vous allez donc tout naturellement passer à des campagnes ciblées, sur des sujets ou des offres spécifiques à communiquer à une petite partie de votre clientèle, particulièrement intéressée par ce que vous avez à lui proposer.
Pourquoi les équipes CRM mettent-elles en place des campagnes ciblées ? Les raisons sont nombreuses :
Pour atteindre vos objectifs, vos campagnes ciblées doivent répondre à un impératif : être aussi pertinentes que possible.
Et leur succès repose sur l’hypothèse que votre équipe CRM sera capable d’identifier, pour chaque campagne ciblée, le segment de clients le plus intéressé par votre campagne.
Alors comment rendre une campagne pertinente ? Une équipe CRM doit identifier, pour chaque campagne ciblée, le segment de clients qui sera intéressé par le ou les sujets de sa campagne, qui s’engagera et finira par convertir.
Ça vous semble facile ? Détrompez-vous.
En tant que marketeurs, nous avons tous appris à segmenter notre marché et à catégoriser nos clients dans des cases bien définies. C’est devenu une telle habitude que nous en oublions parfois que nos clients sont de vraies personnes, dans toute leur complexité, avec leurs envies, leurs caprices, leurs idées, leur spontanéité – en bref, tout ce qui les rend humains.
Les meilleur·e·s d’entre vous n’oublierons peut-être pas… mais quelles options vous reste-t-il ?
Les outils de segmentation traditionnels reposent sur des présupposés qui orientent les audiences créées.
En pratique, voici à quoi cela ressemble :

Bien sûr, c’est un peu caricatural. J’espère que la campagne de cette petite bande dessinée réussira quand même à générer des ventes. Mais vous comprenez sûrement ce que je veux dire. L’approche traditionnelle du ciblage de campagnes, basée sur un ensemble de présupposés, présente de nombreux défauts.
Les données first-party de votre base CRM sont certainement très riches. Vous avez tellement de points de données sur vos clients, leur comportement et vos produits.
Et pourtant, lorsque vous construisez des audiences avec la méthode décrite juste au-dessus, une double simplification s’opère, généralement orientée par vos présupposés :
Pour ces deux dimensions et ces deux valeurs, vos paramètres seront guidés par l’intuition (dans le meilleur des cas) ou par vos présupposés (dans le pire des cas) et seront donc toujours influencés par vos biais personnels.
Par conséquent, vous pouvez deviner mon prochain point…
Parce que cette méthode n’est qu’une tentative très approximative de « prédire » la pertinence de vos campagnes :
La prise en compte de l’historique d’achat pour prédire les achats futurs enfermera malheureusement vos clients dans leurs catégories de départ et vous manquerez l’occasion de leur communiquer des offres supplémentaires, même si ces offres pourraient être pertinentes pour eux.
L’un des pièges de la multiplication des critères pour affiner votre audience est de trop réduire sa taille. Il est fréquent que les marketeurs réalisent que leur audience finale est trop restreinte. Ils devront alors faire des compromis, ajouter de nouveaux segments, supprimer certains critères… pour se retrouver à leur point de départ : une audience large et mal définie.
Lorsque vous créez une audience, il ne vous suffit pas de prédire sa propension à acheter un produit donné. Vous devez en réalité prédire sa propension à acheter au moment de l’envoi de la campagne.
Il ne vous suffit pas de dire « Steve a acheté une robe au cours des 6 derniers mois, donc Steve achètera probablement une autre robe un jour » pour inclure Steve dans votre campagne sur les robes. Sur une très longue période, cette affirmation a de bonnes chances de devenir vraie, mais cela n’aide pas vraiment la campagne que vous devez envoyer demain.
Il serait beaucoup plus efficace de pouvoir dire : « Steve a une très forte propension à acheter une robe cette semaine, alors incluons-le dans la campagne de demain ».
J’espère que nous sommes maintenant aligné·e·s sur les limites des méthodes traditionnelles de construction d’audience.
Heureusement, il existe une solution, et c’est, bien sûr, l’intelligence artificielle.
Plus précisément, le deep learning.
Quand on y pense, c’est plutôt logique :
Vous pourriez vous demander quels sont les points communs entre la création d’une audience et la reconnaissance d’images. Les voilà :


5. Cependant, dans les deux cas, il est possible de rassembler un grand nombre d’exemples pour lesquels une réponse à la question a déjà été donnée.
Nous savons que le deep learning fonctionne étonnamment bien pour la reconnaissance d’images. Avec un ensemble de données suffisamment grand pour entraîner les modèles, le taux de réussite est proche de 100 %. Pour certaines applications spécifiques (l’imagerie médicale par exemple), les modèles de deep learning sont déjà plus efficaces que les humains !
Le deep learning appliqué à la reconnaissance d’images (et en général) fonctionne un peu comme le cerveau humain : de la même manière qu’un enfant apprend à reconnaître un chat, non pas parce qu’il apprend une liste de critères fournis par ses parents, mais parce que ceux-ci lui montrent patiemment des animaux de compagnie et lui disent « ceci est un chat », « ceci est un chien ».
Le deep learning appliqué au CRM fonctionne à peu près de la même manière. L’algorithme basera son apprentissage sur l’intégralité de votre base de données, véritable trésor de données first-party dont nous avons déjà parlé, sans écarter aucun point de données ou s’encombrer de règles arbitraires. Il intégrera tous les cas limites, que vos critères intuitifs n’auraient jamais pu identifier, et les prendra en compte pour ajuster ses prédictions.
L’algorithme de deep learning sera capable de détecter des données très subtiles telles que le cycle de vie des produits, la saisonnalité, le « style » des gens, leur « imprévisibilité »… sans qu’aucune de ces dimensions ne soit inscrite en tant que telle dans votre base de données.
Le deep learning peut prédire avec précision que Marie va acheter une robe à fleurs vintage, même si elle n’a jamais acheté de robe chez vous auparavant, ou de produits “vintage” ou “à fleurs”, pour tout vous dire.
Bien entendu, tout ce dont je viens de vous parler ne s’applique qu’à un algorithme de deep learning bien conçu. Il ne vous suffira pas de charger des tableaux de données CRM dans un algorithme de reconnaissance d’images pour obtenir des prévisions sur les intentions d’achat.
De même, nous savons tous que l’intelligence artificielle et le deep learning sont des termes bien à la mode. Voici donc quelques points qu’il est bon de garder à l’esprit lorsque vous envisagez d’intégrer de l’intelligence artificielle ou du deep learning dans votre stratégie CRM (!):
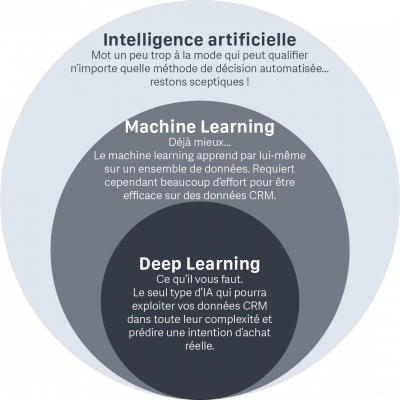
Bingo ! Il semble que le deep learning soit donc la forme d’intelligence artificielle la plus appropriée pour prédire la propension à l’achat.
Restent quelques questions essentielles au sujet du deep learning :
Comme c’est souvent le cas, la valeur réelle d’un algorithme réside dans son utilisation et son exécution. C’est pourquoi un grand nombre de modèles de “deep learning” sont en libre accès ou vendus commercialement. Même s’il s’agit de très bonnes bases pour vos algorithmes, elles ne vous mèneront pas très loin dans votre usage quotidien.
C’est également la raison pour laquelle, de manière générale, vous devriez vous méfier des applications d’IA, de machine learning ou de deep learning qui n’ont pas été développées pour un usage bien défini, mais pour une grande variété de cas d’utilisation. Einstein, Watson, ça vous dit quelque chose ?
Les modèles d’IA ou de deep learning ne sont pas tous créés égaux.
Pour que le deep learning puisse être appliqué avec succès à la construction d’audiences CRM, il doit suivre certains principes de base :
Sans ces deux qualités, une application ne serait jamais utilisée.
Voici quelques évidences sur une bonne application de deep learning appliquée au CRM :
Toutes ces affirmations semblent plutôt évidentes, et c’est bien pourquoi ces applications sont appelées « solutions » et non « problèmes » ! Mais vous pourriez être surpris par le nombre de « solutions » qui ne cochent pas ces trois cases.
***
Ceci étant dit, passons aux choses sérieuses.
Que leurs données ne sont toujours pas “propres” : harmonieuses, ordonnées, exploitables.
Non, les données “propres” n’existent pas.
Nous devons vivre avec et tout de même obtenir les résultats pour lesquels nous sommes attendus. La bonne nouvelle, c’est que c’est tout à fait réalisable si le modèle a été développé en tenant compte de cette contrainte.
C’est assez évident, tant du point de vue de l’efficacité que de la praticité. Les marketeurs veulent obtenir des résultats dès le premier jour d’utilisation, c’est non négociable. Les modèles de deep learning doivent donc être capables d’apprendre à partir de données historiques et avoir une grande qualité prédictive, dès le départ. (Pour en savoir plus, lisez l’article de l’un de nos data scientists – il est un peu plus technique que ce que vous êtes en train de lire, vous serez prévenus !).
C’est surtout une question d’efficacité : si ces tendances et comportements ne sont pas reflétés dans les prédictions, les résultats seront alors au mieux médiocres. Les habitudes d’achat sont très différentes pendant les fêtes de fin d’année et au début du printemps par exemple !
Pour mieux tenir compte de la saisonnalité, le modèle doit être réglé de manière à accorder une attention particulière aux achats les plus récents de l’offre pour laquelle il prédit la propension !
Les revenus, dans la plupart des cas, plutôt que les taux d’ouverture, les taux de clic, etc.
Pendant une semaine donnée, peut-être que 2 % de vos clients vont visiter votre site Web ou effectuer une transaction, source de nouveaux points de données.
Et sur 3 ou 6 mois, peut-être atteindrez-vous 20 ou 30 % d’entre eux ?
Mais qu’en est-il de tous les autres, la grande majorité de vos clients, pour lesquels vous ne disposez pas de données récentes ? Vous aimeriez quand même être en mesure de leur envoyer des communications pertinentes. Il se pourra même qu’ils soient inactifs, rendant leur réactivation encore plus nécessaire. C’est le défaut de nombreuses solutions de personnalisation ou de recommandation de produits : elles fonctionnent bien pour les clients dont les données d’intention sont très récentes, mais sont absolument inefficaces pour tous les autres.
En effet, nous sommes très peu nombreux à n’acheter que des robes, que des tapis ou que des vols pour Miami. Si Jean a déjà acheté des chaussettes chez vous, allez-vous lui envoyer uniquement des campagnes sur les chaussettes ? Si Marie a visité votre hôtel à Bordeaux dans le passé, sera-t-elle condamnée à recevoir vos offres « Week-end à Bordeaux » pour l’éternité ? Et si Marie n’aimait pas visiter deux fois le même endroit ?
***
Comme nous l’avons vu ensemble, le développement d’un modèle de deep learning dédié à la prédiction de la propension d’achat à partir d’un ensemble de données CRM implique de se poser de nombreuses questions. Si nombreuses à vrai dire , que cela ne vaut jamais la peine pour une entreprise de construire son propre modèle en interne : le niveau d’expertise et le temps de développement nécessaire devraient en dissuader plus d’un…
Cependant, pour une équipe d’experts en data science, dont le seul objectif depuis des années est de créer et d’affiner un tel modèle, c’est possible ! Et ces recherches trouvent de nombreuses applications concrètes dans le domaine du marketing CRM.
Les applications pratiques de la capacité à prédire précisément la propension d’achat de chaque client de votre base pour un produit ou une offre de votre catalogue sont infinies. En voici quelques-unes :
La première application pratique est bien évidemment la création d’audience (bien vu, c’est le sujet de cet article).
Disons que votre algorithme de deep learning peut classer tous vos clients du plus susceptible au moins susceptible d’acheter un produit donné. Dans ce cas, la création de l’audience pourrait simplement revenir à :
Les équipes CRM envoient de nombreuses campagnes chaque semaine, parfois plusieurs par jour. Mais elles peuvent avoir une règle selon laquelle aucun client ne doit recevoir plus de 3 messages par semaine, ou plus d’un message par jour.
Mais que se passe-t-il si un client a une très forte propension à acheter chacun des produits présentés dans les campagnes prévues pour une même journée ?
Les informations relatives à la propension d’achat pourraient être utilisées par l’algorithme pour affecter ce client à la campagne pour laquelle sa propension à acheter sera la plus élevée, assurant ainsi une pertinence maximale de vos messages tout en minimisant sa fatigue.
Si vous pouvez obtenir la propension d’achat d’un client / produit, il n’y a aucune raison pour que vous ne puissiez pas obtenir la propension d’achat d’un client / produit / canal.
Cela ajoute une nouvelle dimension à tout ce que nous nous sommes dit jusque là !
Il existe peut-être un petit groupe de vos clients très friand d’un produit donné en ce moment. Il ne sera pas visible dans vos indicateurs clés car il ne figurera pas encore parmi les « meilleures ventes »… mais il existe une forte demande concentrée sur ce petit nombre de personnes. C’est l’audience idéale pour une campagne de CRM ciblée !
Ces informations pourraient par exemple être utilisées pour créer une heat map de votre catalogue de produits, vous permettant de visualiser facilement toutes ces opportunités.
Faut-il mettre en avant deux produits dans la même campagne ou dans deux campagnes distinctes ?
La réponse dépend du fait de savoir si les personnes intéressées par un produit le seront également par l’autre.
Devinez donc comment obtenir cette information…
Si vous êtes arrivé jusqu’ici dans cet article, je vous en remercie ! J’espère que vous y aurez appris plein de choses.
Si vous voulez en savoir plus, n’hésitez pas à jeter un coup d’oeil à tous nos articles.
Sommaire

